
How to use R with BigQuery
Do you want to assess knowledge that resides in Google BigQuery as portion of an R workflow? Thanks to the bigrquery R offer, it is a quite seamless experience — at the time you know a few of modest tweaks wanted to operate dplyr features on these knowledge.
To start with, though, you’ll require a Google Cloud account. Note that you’ll require your personal Google Cloud account even if the knowledge is in somebody else’s account and you really don’t approach on storing your personal knowledge.
How to established up a Google Cloud account
Lots of persons by now have basic Google accounts for use with products and services like Google Push or Gmail. If you really don’t have 1 still, make confident to make 1.
Then, head to the Google Cloud Console at https://console.cloud.google.com, log in with your Google account, and make a new cloud undertaking. R veterans be aware: Although jobs are a superior plan when operating in RStudio, they are necessary in Google Cloud.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGClick the New Venture possibility in order to make a new undertaking.
You must see the possibility to make a new undertaking at the left facet of Google Cloud’s top rated navigation bar. Click on the dropdown menu to the ideal of “Google Cloud Platform” (it may possibly say “select project” if you really don’t have any jobs by now). Give your undertaking a identify. If you have billing enabled by now in your Google account you’ll be required to decide on a billing account if you really don’t, that possibly will not show up as an possibility. Then click ”Create.”
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGIf you really don’t like the default undertaking ID assigned to your undertaking, you can edit it just before clicking the Generate button.
If you really don’t like the undertaking ID that is instantly produced for your undertaking, you can edit it, assuming you really don’t decide one thing that is by now taken.
Make BigQuery easier to find
Once you end your new undertaking set up, you’ll see a basic Google Cloud dashboard that may appear a bit too much to handle. What are all these factors and where is BigQuery? You possibly really don’t require to fear about most of the other products and services, but you do want to be ready to simply find BigQuery in the midst of them all.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGThe preliminary Google Cloud household display can be a bit too much to handle if you are seeking to use just 1 service. (I have since deleted this undertaking.)
Just one way is to “pin” BigQuery to the top rated of your left navigation menu. (If you really don’t see a left nav, click the a few-line “hamburger” at the pretty top rated left to open up it.) Scroll all of the way down, find BigQuery, hover your mouse above it right up until you see a pin icon, and click the pin.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGScroll down to the bottom of the left navigation in the primary Google Cloud household display to find the BigQuery service. You can “pin” it by mousing above right up until you see the pin icon and then clicking on it.
Now BigQuery will normally display up at the top rated of your Google Cloud Console left navigation menu. Scroll back again up and you’ll see BigQuery. Click on it, and you’ll get to the BigQuery console with the identify of your undertaking and no knowledge inside of.
If the Editor tab isn’t right away obvious, click on the “Compose New Query” button at the top rated ideal.
Start out playing with general public knowledge
Now what? People today usually get started learning BigQuery by playing with an readily available general public knowledge established. You can pin other users’ general public knowledge jobs to your personal undertaking, which include a suite of knowledge sets collected by Google. If you go to this URL in the exact BigQuery browser tab you’ve been operating in, the Google general public knowledge undertaking must instantly pin itself to your undertaking.
Thanks to JohannesNE on GitHub for this idea: You can pin any knowledge established you can obtain by working with the URL framework shown below.
https://console.cloud.google.com/bigquery?p=undertaking-id&webpage=undertaking
If this does not work, check to make confident you’re in the ideal Google account. If you’ve logged into far more than 1 Google account in a browser, you may have been despatched to a diverse account than you predicted.
Following pinning a undertaking, click on the triangle to the left of the identify of that pinned undertaking (in this case bigquery-general public-knowledge) and you’ll see all knowledge sets readily available in that undertaking. A BigQuery knowledge established is like a conventional database: It has 1 or far more knowledge tables. Click on the triangle subsequent to a knowledge established to see the tables it consists of.
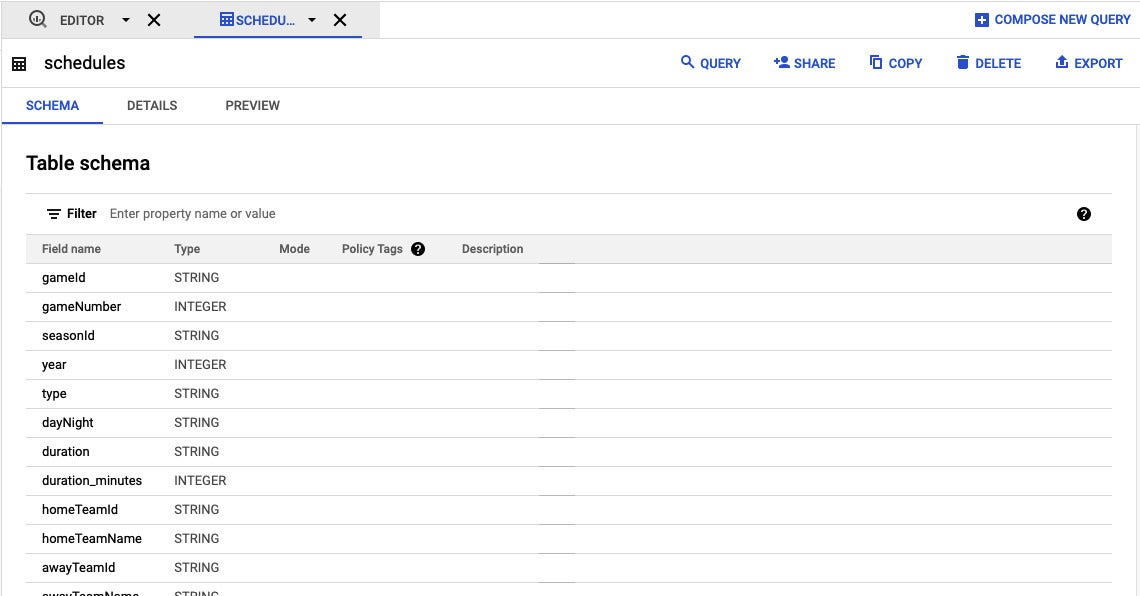 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGClicking on a desk in the BigQuery world-wide-web interface allows you see its schema, along with a tab for previewing knowledge.
Click on the desk identify to see its schema. There is also a “Preview” tab that allows you check out some actual knowledge.
There are other, much less position-and-click methods to see your knowledge framework. But initial….
How BigQuery pricing works
BigQuery prices for both knowledge storage and knowledge queries. When working with a knowledge established made by somebody else, they fork out for the storage. If you make and retail outlet your personal knowledge in BigQuery, you fork out — and the amount is the exact no matter whether you are the only 1 working with it, you share it with a handful of other persons, or you make it general public. (You get 10 GB of cost-free storage for each thirty day period.)
Note that if you operate investigation on somebody else’s knowledge and retail outlet the effects in BigQuery, the new desk turns into portion of your storage allocation.
Enjoy your query costs!
The price of a query is based on how substantially knowledge the query procedures and not how substantially knowledge is returned. This is significant. If your query returns only the top rated 10 effects after analyzing a four GB knowledge established, the query will still use four GB of your knowledge investigation quota, not only the little volume relevant to your 10 rows of effects.
You get one TB of knowledge queries cost-free each individual thirty day period each individual extra TB of knowledge processed for investigation costs $five.
If you’re working SQL queries right on the knowledge, Google advises in no way working a Find * command, which goes as a result of all readily available columns. Instead, Find only the particular columns you require to minimize down on the knowledge that demands to be processed. This not only retains your costs down it also tends to make your queries operate faster. I do the exact with my R dplyr queries, and make confident to decide on only the columns I require.
If you’re asking yourself how you can potentially know how substantially knowledge your query will use just before it runs, there’s an easy respond to. In the BigQuery cloud editor, you can kind a query without working it and then see how substantially knowledge it will system, as shown in the screenshot below.
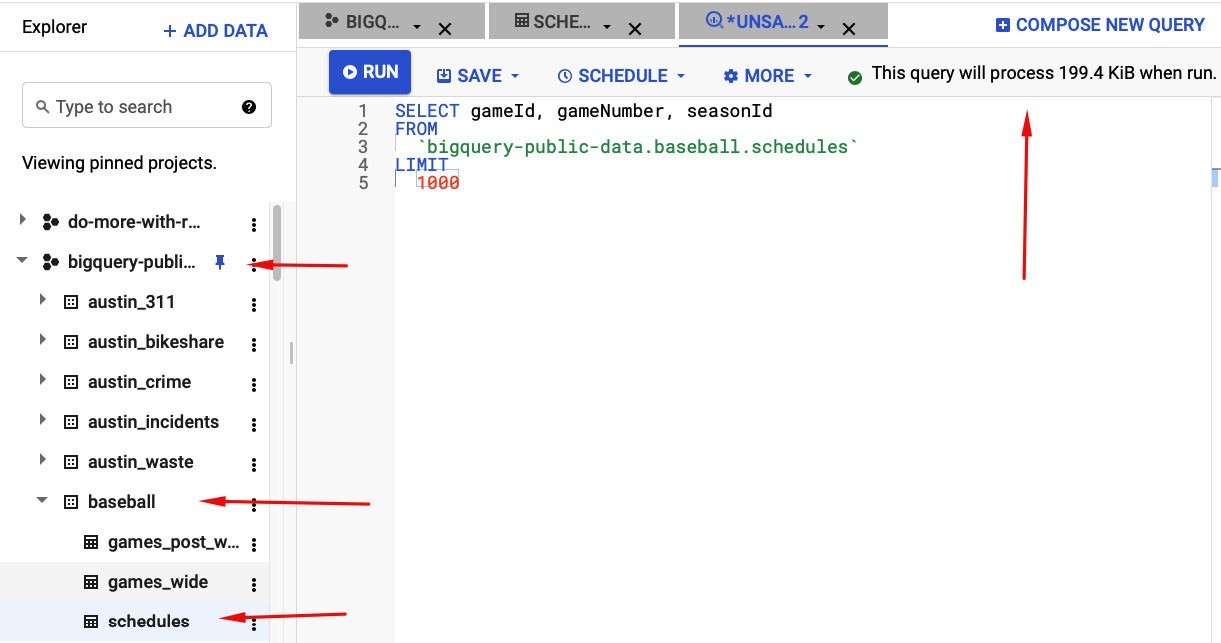 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGUtilizing the BigQuery SQL editor in the world-wide-web interface, you can find your desk underneath its knowledge established and undertaking. Typing in a query without working it reveals how substantially knowledge it will system. Bear in mind to use `projectname.datasetname.tablename` in your query
Even if you really don’t know SQL, you can do a very simple SQL column variety to get an plan of the cost in R, since any extra filtering or aggregating does not lessen the volume of knowledge analyzed.
So, if your query is working above a few columns named columnA, columnB, and columnC in desk-id, and desk-id is in dataset-id which is portion of undertaking-id, you can only kind the adhering to into the query editor:
Find columnA, columnB, columnC FROM `project-id.dataset-id.desk-id`
Really don’t operate the query, just kind it and then look at the line at the top rated ideal to see how substantially knowledge will be employed. Whichever else your R code will be performing with that knowledge should not matter for the query cost.
In the screenshot earlier mentioned, you can see that I have selected a few columns from the schedules desk, which is portion of the baseball knowledge established, which is portion of the bigquery-general public-knowledge undertaking.
Queries on metadata are cost-free, but you require to make confident you’re thoroughly structuring your query to qualify for that. For example, working with Find Count(*) to get the amount of rows in a knowledge established isn’t charged.
There are other factors you can do to restrict costs. For far more suggestions, see Google’s “Controlling costs in BigQuery” webpage.
Do I require to enter a credit card to use BigQuery?
No, you really don’t require a credit card to get started working with BigQuery. But without billing enabled, your account is a BigQuery “sandbox” and not all queries will work. I strongly counsel incorporating a billing supply to your account even if you’re highly unlikely to exceed your quota of cost-free BigQuery investigation.
Now — at last! — let’s look at how to tap into BigQuery with R.
Connect to BigQuery knowledge established in R
I’ll be working with the bigrquery offer in this tutorial, but there are other options you may want to consider, which include the obdc offer or RStudio’s specialist drivers and 1 of its company solutions.
To query BigQuery knowledge with R and bigrquery, you initial require to established up a link to a knowledge established working with this syntax:
library(bigrquery)
con <- dbConnect(
bigquery(),
project = undertaking_id_containing_the_knowledge,
dataset = database_identify
billing = your_undertaking_id_with_the_billing_supply
)
The initial argument is the bigquery() operate from the bigrquery offer, telling dbConnect that you want to join to a BigQuery knowledge supply. The other arguments define the undertaking ID, knowledge established identify, and billing undertaking ID.
(Connection objects can be termed quite substantially anything at all, but by convention they are usually named con.)
The code below loads the bigrquery and dplyr libraries and then generates a link to the schedules desk in the baseball knowledge established.
bigquery-general public-knowledge is the undertaking argument because which is where the knowledge established lives. my_undertaking_id is the billing argument because my project’s quota will be “billed” for queries.
library(bigrquery)
library(dplyr)
con <- dbConnect(
bigrquery::bigquery(),
undertaking = "bigquery-general public-knowledge",
dataset = "baseball",
billing = "my_undertaking_id"
)
Very little substantially happens when I operate this code apart from generating a link variable. But the initial time I test to use the link, I’ll be asked to authenticate my Google account in a browser window.
For example, to listing all readily available tables in the baseball knowledge established, I’d operate this code:
dbListTables(con)
# You will be asked to authenticate in your browser
How to query a BigQuery desk in R
To query 1 particular BigQuery desk in R, use dplyr’s tbl() operate to make a desk item that references the desk, these as this for the schedules desk working with my freshly made link to the baseball knowledge established:
skeds <- tbl(con, "schedules")
If you use the foundation R str() command to analyze skeds’ framework, you’ll see a listing, not a knowledge frame:
str(skeds) List of 2 $ src:List of 2 ..$ con :Formal course 'BigQueryConnection' [offer "bigrquery"] with seven slots .. .. ..@ undertaking : chr "bigquery-general public-knowledge" .. .. ..@ dataset : chr "baseball" .. .. ..@ billing : chr "do-far more-with-r-242314" .. .. ..@ use_legacy_sql: logi Fake .. .. ..@ webpage_dimensions : int 10000 .. .. ..@ tranquil : logi NA .. .. ..@ bigint : chr "integer" ..$ disco: NULL ..- attr(*, "course")= chr [one:four] "src_BigQueryConnection" "src_dbi" "src_sql" "src" $ ops:List of 2 ..$ x : 'ident' chr "schedules" ..$ vars: chr [one:sixteen] "gameId" "gameNumber" "seasonId" "year" ... ..- attr(*, "course")= chr [one:three] "op_foundation_remote" "op_foundation" "op" - attr(*, "course")= chr [one:five] "tbl_BigQueryConnection" "tbl_dbi" "tbl_sql" "tbl_lazy" ...
The good news is, dplyr features these as glimpse() usually work quite seamlessly with this kind of item (course tbl_BigQueryConnection).
Running glimpse(skeds) will return mainly what you expect — apart from it does not know how a lot of rows are in the knowledge.
glimpse(skeds)
Rows: ??
Columns: sixteen
Database: BigQueryConnection
$ gameId"e14b6493-9e7f-404f-840a-8a680cc364bf", "1f32b347-cbcb-4c31-a145-0e…
$ gameNumberone, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, 1…
$ seasonId"565de4be-dc80-4849-a7e1-54bc79156cc8", "565de4be-dc80-4849-a7e1-54…
$ year2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2…
$ kind"REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG…
$ dayNight"D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D…
$ duration"three:07", "three:09", "2:45", "three:forty two", "2:forty four", "three:21", "2:53", "2:56", "three:…
$ duration_minutes187, 189, one hundred sixty five, 222, 164, 201, 173, 176, a hundred and eighty, 157, 218, a hundred and sixty, 178, 20…
$ homeTeamId"03556285-bdbb-4576-a06d-42f71f46ddc5", "03556285-bdbb-4576-a06d-42…
$ homeTeamName"Marlins", "Marlins", "Braves", "Braves", "Phillies", "Diamondbacks…
$ awayTeamId"55714da8-fcaf-4574-8443-59bfb511a524", "55714da8-fcaf-4574-8443-59…
$ awayTeamName"Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cu…
$ startTime2016-06-26 17:10:00, 2016-06-25 20:10:00, 2016-06-11 20:10:00, 201…
$ attendance27318, 29457, 43114, 31625, 28650, 33258, 23450, 32358, 46206, 4470…
$ standing"closed", "closed", "closed", "closed", "closed", "closed", "closed…
$ made2016-10-06 06:25:fifteen, 2016-10-06 06:25:fifteen, 2016-10-06 06:25:fifteen, 201…
That tells me glimpse() may not be parsing as a result of the full knowledge established — and suggests there’s a superior chance it is not working up query prices but is as a substitute querying metadata. When I checked my BigQuery world-wide-web interface after working that command, there in truth was no query cost.
BigQuery + dplyr investigation
You can operate dplyr commands on desk objects pretty much the exact way as you do on conventional knowledge frames. But you’ll possibly want 1 addition: piping effects from your normal dplyr workflow into the gather() operate.
The code below uses dplyr to see what yrs and household teams are in the skeds desk item and saves the effects to a tibble (special kind of knowledge frame employed by the tidyverse suite of packages).
readily available_teams <- select(skeds, homeTeamName) {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
distinctive() {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
gather()
Comprehensive
Billed: 10.forty nine MB
Downloading 31 rows in one webpages.
Pricing be aware: I checked the earlier mentioned query working with a SQL statement searching for the exact data:
Find Unique `homeTeamName`
FROM `bigquery-general public-knowledge.baseball.schedules`
When I did, the BigQuery world-wide-web editor confirmed that only 21.one KiB of knowledge had been processed, not far more than 10 MB. Why was I billed so substantially far more? Queries have a 10 MB bare minimum (and are rounded up to the subsequent MB).
Apart: If you want to retail outlet effects of an R query in a short-term BigQuery desk as a substitute of a area knowledge frame, you could increase compute(identify = “my_temp_table”) to the finish of your pipe as a substitute of gather(). However, you’d require to be operating in a undertaking where you have permission to make tables, and Google’s general public knowledge undertaking is unquestionably not that.
If you operate the exact code without gather(), these as
readily available_teams <- select(skeds, homeTeamName) {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
distinctive()
you are preserving the query and not the effects of the query. Note that readily available_teams is now a query item with classes tbl_sql, tbl_BigQueryConnection, tbl_dbi, and tbl_lazy (lazy that means it will not operate except if exclusively invoked).
You can operate the saved query by working with the item identify by itself in a script:
readily available_teams
See the SQL dplyr generates
You can see the SQL being produced by your dplyr statements with display_query() at the finish of your chained pipes:
decide on(skeds, homeTeamName) {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
distinctive() {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
display_query()
Find Unique `homeTeamName`
FROM `schedules`
You can minimize and paste this SQL into the BigQuery world-wide-web interface to see how substantially knowledge you’ll use. Just keep in mind to change the plain desk identify these as `schedules` to the syntax `project.dataset.tablename` in this case, `bigquery-general public-knowledge.baseball.schedules`.
If you operate the exact specific query a next time in your R session, you will not be billed once again for knowledge investigation because BigQuery will use cached effects.
Operate SQL on BigQuery inside R
If you’re at ease composing SQL queries, you can also operate SQL commands inside R if you want to pull knowledge from BigQuery as portion of a bigger R workflow.
For example, let’s say you want to operate this SQL command:
Find Unique `homeTeamName` from `bigquery-general public-knowledge.baseball.schedules`
You can do so inside R by working with the DBI package’s dbGetQuery() operate. Right here is the code:
sql <- "SELECT DISTINCT homeTeamName from bigquery-public-data.baseball.schedules" library(DBI) my_results <- dbGetQuery(con, sql) Complete Billed: 10.49 MB Downloading 31 rows in 1 pages
Note that I was billed once again for the query because BigQuery does not consider 1 query in R and a further in SQL to be specifically the exact, even if they are searching for the exact knowledge.
If I operate that SQL query once again, I will not be billed.
my_results2 <- dbGetQuery(con, sql) Complete Billed: 0 B Downloading 31 rows in 1 pages.
BigQuery and R
Following the 1-time preliminary set up, it is as easy to assess BigQuery knowledge in R as it is to operate dplyr code on a area knowledge frame. Just hold your query costs in intellect. If you’re working a dozen or so queries on a 10 GB knowledge established, you will not occur near to hitting your one TB cost-free regular quota. But if you’re operating on bigger knowledge sets each day, it is really worth seeking at methods to streamline your code.
For far more R suggestions and tutorials, head to my Do More With R page.
Copyright © 2021 IDG Communications, Inc.






