
How to search Twitter with rtweet and R
Twitter is a good supply of information about R — primarily during conferences like Consumer! and RStudio Convention. And many thanks to R and the rtweet deal, you can establish your individual device to download tweets for easy looking, sorting, and filtering. Let’s acquire a glimpse, phase by phase.
First you want to put in any of the rtweet project’s packages you never now have: rtweet, reactable, glue, stringr, httpuv, and dplyr. Then to start off, load rtweet and dplyr.
# If you need to put in any of these:
# put in.packages("rtweet")
# put in.packages("reactable")
# put in.packages("glue")
# put in.packages("stringr")
# put in.packages("httpuv")
# put in.packages("dplyr")
# put in.packages("purrr")
library(rtweet)
library(dplyr)
Authorize the Twitter API
To use rtweet, you need a Twitter account so you can authorize rtweet to use your particular account credentials. That is because there is a limit to how several tweets you can download in a 15-moment time period.
Michael Kearney, who wrote rtweet, gives rtweet end users two options. The best way is to only ask for some tweets. If there are not credentials saved on your system, a browser window should open inquiring you to authorize the ask for. Soon after that, an authorization token will be saved in your .Renviron file so you never have to re-authorize in the upcoming.
You can go to rtweet.facts to see the other method, which includes location up a Twitter developer account and a new job to make authorization credentials. If you are going to use rtweet a lot, you are going to possibly want to do that. But to start off, the less difficult way is, well, less difficult.
Import tweets
To search for tweets with a particular hashtag (or phrase that is not a hashtag), you use the intuitively named search_tweets() operate. It takes numerous arguments, which include the question, such as #rstudioconf or #rstats regardless of whether you want to consist of retweets and the selection of tweets to return. The selection defaults to a hundred.
Whilst you can acquire up to eighteen,000 tweets within 15 minutes, there is an vital restriction when applying the Twitter API to search for a word or phrase: search final results only go back six to 9 times unless you shell out for a top quality Twitter API account. Contrary to the Twitter internet site, you can’t use rtweet to search for tweets from a conference very last calendar year. You will not be capable to search two weeks right after a conference to get individuals tweets. So you are going to want to make sure to save tweets you pull now that you may possibly want in the upcoming.
There are additional arguments you can use to customize your search, but let’s start off with a simple search: 200 tweets with the #rstudioconf hashtag, without the need of retweets.
tweet_df <- search_tweets("#rstudioconf", n = 200,
consist of_rts = Fake)
If you operate that code and by no means utilised rtweet before, you will be questioned to authorize a Twitter app.
Be aware that even although you talk to for 200 tweets, you may possibly get back much less. One motive is that there may possibly not be 200 tweets for your question in the very last six to 9 times. One more is that Twitter may possibly in truth have in the beginning extracted 200 tweets, but right after filtering out retweets, much less were left.
The tweet_df details body will come back with ninety columns of details for every tweet:
 Sharon Machlis, IDG
Sharon Machlis, IDGAn rtweet details body of tweets returns with ninety columns.
The columns I’m usually most interested in are standing_id, made_at, monitor_title, text, favored_count, retweet_count, and urls_expanded_url. You may possibly want some other columns for your examination but for this tutorial, I’ll find just individuals columns.
Search, filter, and evaluate your tweets
There are loads of interesting visualizations and analyses you can do with Twitter details and R. Some of them are created proper into rtweet. But I’m producing this tutorial carrying my tech journalist hat. I want an easy way to see new and amazing issues I may possibly not know about.
Most-preferred tweets from a conference may possibly assist with that. And if I use rtweet and the Twitter API, I never have to rely on Twitter’s “popular” algorithm. I can do my individual searches and set my individual conditions for “popular.” I may possibly want to search for major tweets just from the existing day when a conference is in development, or filter for a particular matter I’m interested in — like “shiny” or “purrr” — sorted by most likes or most retweets.
1 of the best ways to do these forms of searches and kinds is with a sortable table. DT is one particular well-known deal for this. But lately I have been experimenting with a different one particular: reactable.
The default reactable() is variety of blah. For case in point:
tweet_table_details <- select(tweets, -user_id, -status_id)
library(reactable)
reactable(tweet_table_details)
This code produces a table that appears like this:
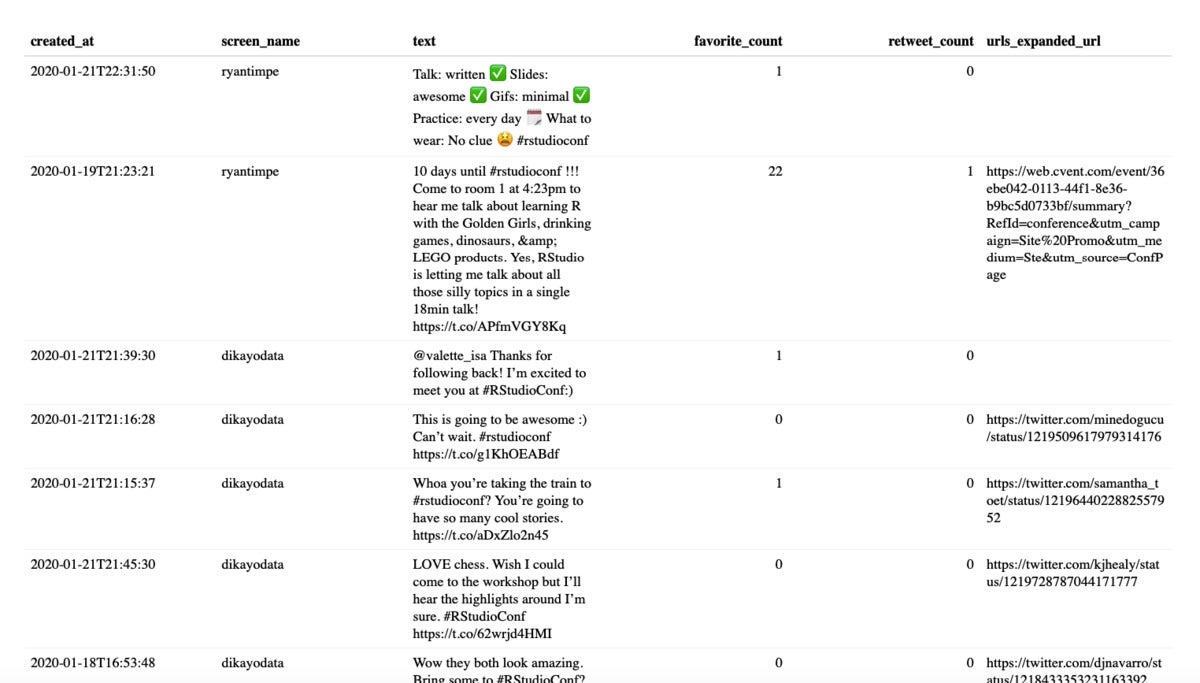 Sharon Machlis, IDG
Sharon Machlis, IDGDefault reactable table of tweets
But we can increase some customizations, such as:
reactable(tweet_table_details,
filterable = Legitimate, searchable = Legitimate, bordered = Legitimate,
striped = Legitimate, highlight = Legitimate,
defaultPageSize = 25, showPageSizeOptions = Legitimate,
showSortable = Legitimate, pageSizeOptions = c(25, fifty, 75, a hundred, 200), defaultSortOrder = "desc",
columns = listing(
made_at = colDef(defaultSortOrder = "asc"),
monitor_title = colDef(defaultSortOrder = "asc"),
text = colDef(html = Legitimate, minWidth = a hundred ninety, resizable = Legitimate),
favored_count = colDef(filterable = Fake),
retweet_count = colDef(filterable = Fake),
urls_expanded_url = colDef(html = Legitimate)
)
)
The result is a table that appears some thing like this:
 Sharon Machlis, IDG
Sharon Machlis, IDGA tailored reactable table of tweets.
Configure your reactable details table
In the code chunk above, the filterable = Legitimate argument added search filters down below every column header, and searchable added the overall table search box at the major proper. Turning on bordered, striped, and highlight does what you may possibly be expecting: Adds a table border, adds alternating-row color “stripes,” and highlights a row if you set a cursor on it.
I set my defaultPageSize to 25. The showPageSizeOptions argument allows me improve the page duration interactively, and then I outline page sizing possibilities that will clearly show up in a drop-down menu down below the table (not visible in the monitor shot). The showSortable argument adds minor arrow icons subsequent to column names so end users know they can simply click to type. And I set every column’s defaultSortOrder to descending in its place of ascending. So if I simply click on the column of selection of retweets or likes, I will see that as most to the very least, not the very least to most.
Eventually, there is the columns argument. That is a listing made up of a column definition for every column. Search at the reactable assist files for additional details on other obtainable possibilities. In this case in point, I set the made_at and monitor_title columns to have a default type purchase of ascending. For the text column, I set it to exhibit HTML as HTML so I can increase clickable backlinks. I also set a bare minimum column width of a hundred ninety pixels and produced the column resizable — so end users can simply click and drag to make it wider or narrower.
I also turned off the filter containers for favored_count and reply_count. That is because, however, reactable filters never have an understanding of when columns are quantities and will filter them as character strings. Whilst reactable kinds selection columns correctly, the filter containers are problematic. That is the significant downside to reactable vs. the DT deal: DT understands column forms and filters accordingly. But sorting numerically is sufficient for me for this intent.
You can verify out the video at the major of this short article to see what it appears like when you type a column or make the tweet text column wider and narrower.
Make your details table additional useful
A pair of issues will make this table additional useful. This code does not exhibit photographs or films incorporated in tweets. That is fine, because my intent here is to scan text, not re-develop a Twitter application. But that suggests it will in some cases be handy to see the initial tweet in purchase to perspective shots, films, or responses.
I think it’s hassle-free to increase a compact clickable some thing at the stop of every tweet’s text that you can simply click to see the genuine tweet on Twitter. I determined on >> although it could be any character or people.
To construct a URL, I need to know the format of a tweet, which if you glimpse at any tweet on the Twitter internet site, you can see is https://twitter.com/username/standing/tweetID.
Utilizing the glue deal, that would be rendered like this:
glue::glue("https://twitter.com/monitor_title/standing/standing_id")
If you haven’t utilised glue before, it’s a good deal for pasting collectively text and variable values. In the above code, any variable title among braces is evaluated.
My whole code to develop a column with a clickable hyperlink to the tweet right after the tweet text:
Tweet = glue::glue("text >> ")
And the code to develop a details body for an interactive table:
tweet_table_details <- tweet_df {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
find(consumer_id, standing_id, made_at, monitor_title, text, favored_count, retweet_count, urls_expanded_url) {d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
mutate(
Tweet = glue::glue("text >> ")
){d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}>{d11068cee6a5c14bc1230e191cd2ec553067ecb641ed9b4e647acef6cc316fdd}
find(DateTime = made_at, Consumer = monitor_title, Tweet, Likes = favored_count, RTs = retweet_count, URLs = urls_expanded_url)
I would also like to make clickable backlinks from the URL column, which is now just text. This is a little bit intricate, because the URL column is a listing column because some tweets consist of additional than one particular URL.
I’m sure there is a additional classy way to develop clickable backlinks from a listing column of plain-text URLs, but the code down below performs. First I develop a operate to make the HTML if there are no URLs, one particular URL, or two or additional:
make_url_html <- function(url)
if(duration(url) < 2)
if(!is.na(url))
as.character(glue("url") )
else
""
else
paste0(purrr::map_chr(url, ~ paste0("", .x, "", collapse = ", ")), collapse = ", ")
I operate purrr::map_chr() on the URL benefit if there are two or additional URLs so that every URL receives its individual HTML then I paste them collectively and collapse them into a one character string to look in the table.
The moment my operate performs, I use purrr::map_chr() once again to iterate over every merchandise in the column:
tweet_table_details$URLs <- purrr::map_chr(tweet_table_data$URLs, make_url_html)
Really do not fret if you never have an understanding of this component, since it’s genuinely additional about purrr and listing columns than rtweet and reactable. And it’s not important to search and type the tweets you can normally simply click to the initial tweet and see clickable backlinks there.
Eventually, I can operate my tailored reactable() code on the new tweet table details:
reactable(tweet_table_details,
filterable = Legitimate, searchable = Legitimate, bordered = Legitimate, striped = Legitimate, highlight = Legitimate,
showSortable = Legitimate, defaultSortOrder = "desc", defaultPageSize = 25, showPageSizeOptions = Legitimate, pageSizeOptions = c(25, fifty, 75, a hundred, 200),
columns = listing(
DateTime = colDef(defaultSortOrder = "asc"),
Consumer = colDef(defaultSortOrder = "asc"),
Tweet = colDef(html = Legitimate, minWidth = a hundred ninety, resizable = Legitimate),
Likes = colDef(filterable = Fake, format = colFormat(separators = Legitimate)),
RTs = colDef(filterable = Fake, format = colFormat(separators = Legitimate)),
URLs = colDef(html = Legitimate)
)
)
If you have been subsequent alongside, you should have your individual interactive table that can search, type, and filter conference or matter tweets.
Recommendations for tweet collectors
1 factor to remember: If you are subsequent a conference hashtag during a conference, you will want to pull sufficient tweets to get the complete conference. So verify the earliest date in your tweet details body. If that date is right after the conference started off, ask for additional tweets. If your conference hashtag has additional than eighteen,000 tweets (as occurred when I was tracking CES) you are going to need to come up with some tactics to get the complete set. Check out out the retryonratelimit argument for search_tweets() if you want to obtain a complete eighteen,000+ set of conference hashtag tweets going back six times or less
Eventually, make sure to save your details to a area file when the conference ends! A week later, you are going to no extended have obtain to individuals tweets by means of search_tweets() and the Twitter API.
In a upcoming “Do Extra with R” episode, I’ll exhibit how to change this into an interactive Shiny app.
For additional R ideas, head to the Do Extra With R page at https://little bit.ly/domorewithR or the Do Extra With R playlist on the IDG TECHtalk YouTube channel.







