
Could Sucking Up the Seafloor Solve Battery Shortage?
Luckily for such synthetic neural networks—later rechristened “deep discovering” when they integrated excess layers of neurons—decades of
Moore’s Legislation and other advancements in laptop components yielded a approximately 10-million-fold boost in the quantity of computations that a laptop could do in a next. So when scientists returned to deep discovering in the late 2000s, they wielded tools equal to the obstacle.
These extra-effective computer systems produced it attainable to assemble networks with vastly extra connections and neurons and consequently bigger capacity to product complicated phenomena. Researchers utilised that capacity to crack history right after history as they used deep discovering to new jobs.
While deep learning’s increase may perhaps have been meteoric, its upcoming may perhaps be bumpy. Like Rosenblatt in advance of them, present-day deep-discovering scientists are nearing the frontier of what their tools can realize. To recognize why this will reshape equipment discovering, you need to 1st recognize why deep discovering has been so profitable and what it prices to preserve it that way.
Deep discovering is a modern day incarnation of the prolonged-managing development in synthetic intelligence that has been going from streamlined methods based on professional knowledge towards flexible statistical designs. Early AI methods had been rule based, making use of logic and professional knowledge to derive benefits. Afterwards methods included discovering to established their adjustable parameters, but these had been normally number of in quantity.
Present-day neural networks also discover parameter values, but individuals parameters are section of such flexible laptop designs that—if they are massive enough—they turn into universal perform approximators, which means they can suit any type of details. This limitless flexibility is the purpose why deep discovering can be used to so numerous distinctive domains.
The flexibility of neural networks will come from using the numerous inputs to the product and possessing the network blend them in myriad methods. This suggests the outputs will never be the consequence of making use of simple formulas but as a substitute immensely complicated ones.
For instance, when the reducing-edge graphic-recognition procedure
Noisy College student converts the pixel values of an graphic into chances for what the item in that graphic is, it does so making use of a network with 480 million parameters. The teaching to verify the values of such a massive quantity of parameters is even extra remarkable due to the fact it was completed with only one.2 million labeled images—which may perhaps understandably confuse individuals of us who keep in mind from high university algebra that we are meant to have extra equations than unknowns. Breaking that rule turns out to be the essential.
Deep-discovering designs are overparameterized, which is to say they have extra parameters than there are details details accessible for teaching. Classically, this would guide to overfitting, where the product not only learns common developments but also the random vagaries of the details it was skilled on. Deep discovering avoids this trap by initializing the parameters randomly and then iteratively modifying sets of them to much better suit the details making use of a approach called stochastic gradient descent. Remarkably, this method has been tested to make sure that the discovered product generalizes very well.
The achievements of flexible deep-discovering designs can be viewed in equipment translation. For a long time, software program has been utilised to translate text from one language to another. Early methods to this challenge utilised guidelines designed by grammar professionals. But as extra textual details became accessible in particular languages, statistical approaches—ones that go by such esoteric names as optimum entropy, hidden Markov designs, and conditional random fields—could be used.
In the beginning, the methods that labored best for every single language differed based on details availability and grammatical attributes. For instance, rule-based methods to translating languages such as Urdu, Arabic, and Malay outperformed statistical ones—at 1st. Currently, all these methods have been outpaced by deep discovering, which has tested alone superior just about all over the place it is used.
So the excellent news is that deep discovering presents great flexibility. The lousy news is that this flexibility will come at an great computational charge. This regrettable fact has two parts.
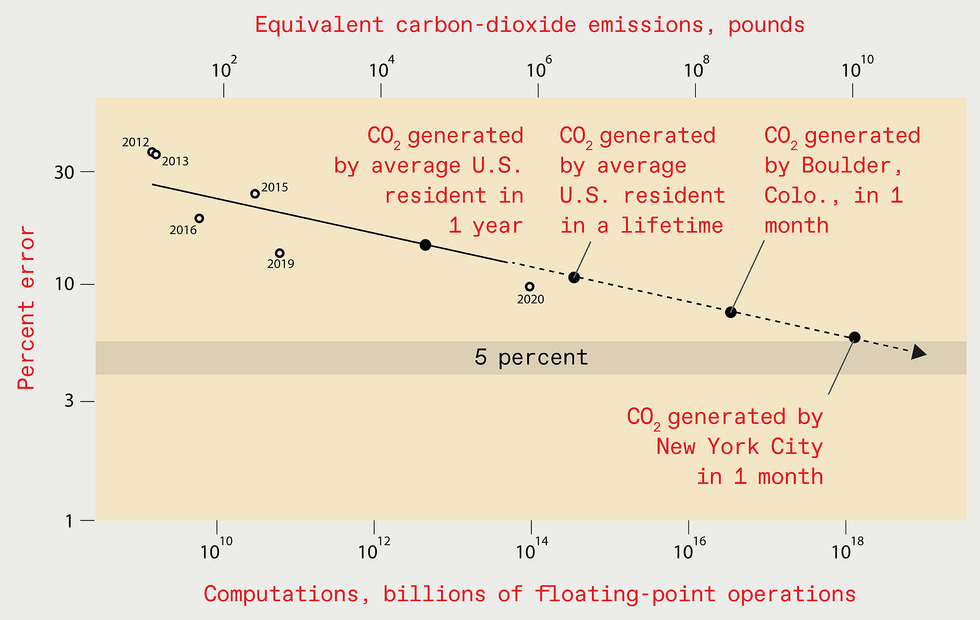
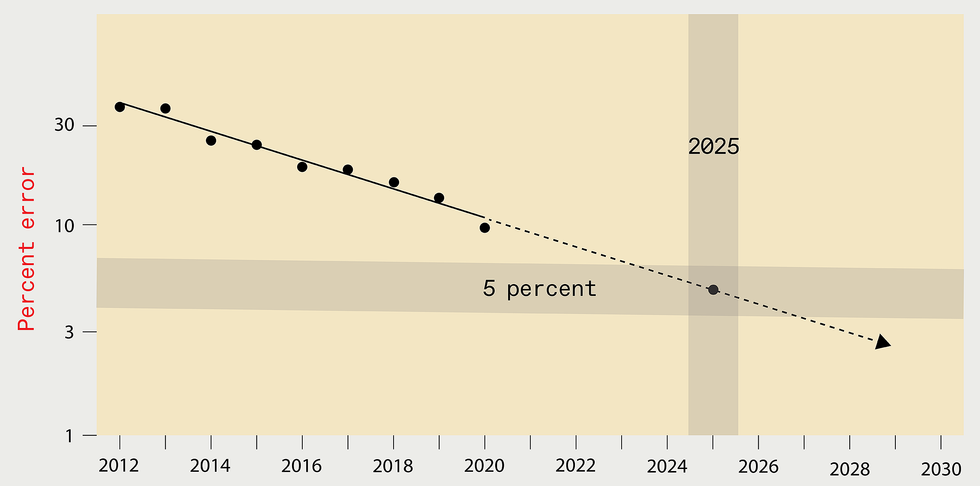
Extrapolating the gains of modern decades could possibly advise that by
2025 the error degree in the best deep-discovering methods designed
for recognizing objects in the ImageNet details established should really be
decreased to just 5 per cent [top rated]. But the computing methods and
power needed to prepare such a upcoming procedure would be great,
foremost to the emission of as significantly carbon dioxide as New York
City generates in one thirty day period [bottom].
Supply: N.C. THOMPSON, K. GREENEWALD, K. LEE, G.F. MANSO
The 1st section is genuine of all statistical designs: To improve general performance by a aspect of
k, at minimum k2 extra details details need to be utilised to prepare the product. The next section of the computational charge will come explicitly from overparameterization. After accounted for, this yields a overall computational charge for enhancement of at minimum k4. That small 4 in the exponent is very costly: A 10-fold enhancement, for instance, would need at minimum a 10,000-fold boost in computation.
To make the flexibility-computation trade-off extra vivid, take into account a state of affairs where you are attempting to predict irrespective of whether a patient’s X-ray reveals cancer. Suppose additional that the genuine remedy can be located if you evaluate a hundred aspects in the X-ray (frequently called variables or features). The obstacle is that we really don’t know ahead of time which variables are vital, and there could be a very massive pool of applicant variables to take into account.
The professional-procedure technique to this challenge would be to have individuals who are educated in radiology and oncology specify the variables they think are vital, letting the procedure to look at only individuals. The flexible-procedure technique is to examination as numerous of the variables as attainable and allow the procedure figure out on its personal which are vital, requiring extra details and incurring significantly increased computational prices in the approach.
Types for which professionals have founded the relevant variables are able to discover speedily what values do the job best for individuals variables, accomplishing so with constrained amounts of computation—which is why they had been so preferred early on. But their capacity to discover stalls if an professional hasn’t correctly specified all the variables that should really be integrated in the product. In distinction, flexible designs like deep discovering are less economical, using vastly extra computation to match the general performance of professional designs. But, with sufficient computation (and details), flexible designs can outperform ones for which professionals have attempted to specify the relevant variables.
Clearly, you can get enhanced general performance from deep discovering if you use extra computing electricity to develop more substantial designs and prepare them with extra details. But how costly will this computational burden turn into? Will prices turn into adequately high that they hinder progress?
To remedy these queries in a concrete way,
we just lately gathered details from extra than one,000 exploration papers on deep discovering, spanning the parts of graphic classification, item detection, question answering, named-entity recognition, and equipment translation. Listed here, we will only focus on graphic classification in element, but the lessons utilize broadly.
More than the decades, lessening graphic-classification errors has occur with an great expansion in computational burden. For instance, in 2012
AlexNet, the product that 1st showed the electricity of teaching deep-discovering methods on graphics processing units (GPUs), was skilled for five to 6 times making use of two GPUs. By 2018, another product, NASNet-A, had cut the error price of AlexNet in 50 %, but it utilised extra than one,000 moments as significantly computing to realize this.
Our examination of this phenomenon also allowed us to examine what is actually in fact took place with theoretical expectations. Concept tells us that computing desires to scale with at minimum the fourth electricity of the enhancement in general performance. In observe, the precise prerequisites have scaled with at minimum the
ninth electricity.
This ninth electricity suggests that to halve the error price, you can count on to have to have extra than 500 moments the computational methods. That’s a devastatingly high price. There may perhaps be a silver lining here, even so. The gap among what is actually took place in observe and what principle predicts could possibly suggest that there are nonetheless undiscovered algorithmic advancements that could drastically improve the effectiveness of deep discovering.
To halve the error price, you can count on to have to have extra than 500 moments the computational methods.
As we observed, Moore’s Legislation and other components improvements have supplied large raises in chip general performance. Does this suggest that the escalation in computing prerequisites does not issue? However, no. Of the one,000-fold distinction in the computing utilised by AlexNet and NASNet-A, only a 6-fold enhancement came from much better components the rest came from making use of extra processors or managing them longer, incurring increased prices.
Having believed the computational charge-general performance curve for graphic recognition, we can use it to estimate how significantly computation would be required to get to even extra remarkable general performance benchmarks in the upcoming. For instance, acquiring a 5 per cent error price would need 10
19 billion floating-issue operations.
Significant do the job by scholars at the College of Massachusetts Amherst will allow us to recognize the economic charge and carbon emissions implied by this computational burden. The responses are grim: Education such a product would charge US $a hundred billion and would create as significantly carbon emissions as New York City does in a thirty day period. And if we estimate the computational burden of a one per cent error price, the benefits are substantially even worse.
Is extrapolating out so numerous orders of magnitude a reasonable point to do? Of course and no. Undoubtedly, it is vital to recognize that the predictions aren’t specific, although with such eye-watering benefits, they really don’t have to have to be to express the over-all concept of unsustainability. Extrapolating this way
would be unreasonable if we assumed that scientists would comply with this trajectory all the way to such an extraordinary end result. We really don’t. Confronted with skyrocketing prices, scientists will possibly have to occur up with extra economical methods to address these issues, or they will abandon doing work on these issues and progress will languish.
On the other hand, extrapolating our benefits is not only reasonable but also vital, due to the fact it conveys the magnitude of the obstacle ahead. The foremost edge of this challenge is presently turning out to be evident. When Google subsidiary
DeepMind skilled its procedure to play Go, it was believed to have charge $35 million. When DeepMind’s scientists designed a procedure to play the StarCraft II video clip video game, they purposefully did not test multiple methods of architecting an vital component, due to the fact the teaching charge would have been as well high.
At
OpenAI, an vital equipment-discovering think tank, scientists just lately designed and skilled a significantly-lauded deep-discovering language procedure called GPT-3 at the charge of extra than $4 million. Even while they produced a oversight when they executed the procedure, they did not correct it, explaining simply just in a complement to their scholarly publication that “thanks to the charge of teaching, it was not possible to retrain the product.”
Even enterprises outdoors the tech industry are now starting up to shy absent from the computational price of deep discovering. A massive European supermarket chain just lately deserted a deep-discovering-based procedure that markedly enhanced its capacity to predict which solutions would be obtained. The enterprise executives dropped that endeavor due to the fact they judged that the charge of teaching and managing the procedure would be as well high.
Confronted with mounting economic and environmental prices, the deep-discovering local community will have to have to discover methods to boost general performance without the need of leading to computing calls for to go by way of the roof. If they really don’t, progress will stagnate. But really don’t despair nevertheless: A great deal is getting completed to tackle this obstacle.
One particular method is to use processors designed specifically to be economical for deep-discovering calculations. This technique was broadly utilised about the previous 10 years, as CPUs gave way to GPUs and, in some situations, discipline-programmable gate arrays and software-particular ICs (which includes Google’s
Tensor Processing Unit). Essentially, all of these methods sacrifice the generality of the computing system for the effectiveness of elevated specialization. But such specialization faces diminishing returns. So longer-phrase gains will need adopting wholly distinctive components frameworks—perhaps components that is based on analog, neuromorphic, optical, or quantum methods. Hence significantly, even so, these wholly distinctive components frameworks have nevertheless to have significantly influence.
We need to possibly adapt how we do deep discovering or facial area a upcoming of significantly slower progress.
Yet another technique to lessening the computational burden focuses on making neural networks that, when executed, are lesser. This tactic lowers the charge every single time you use them, but it frequently raises the teaching charge (what we have explained so significantly in this post). Which of these prices issues most is dependent on the circumstance. For a broadly utilised product, managing prices are the largest component of the overall sum invested. For other models—for instance, individuals that regularly have to have to be retrained— teaching prices may perhaps dominate. In possibly case, the overall charge need to be larger than just the teaching on its personal. So if the teaching prices are as well high, as we have revealed, then the overall prices will be, as well.
And that is the obstacle with the several methods that have been utilised to make implementation lesser: They really don’t decrease teaching prices sufficient. For instance, one will allow for teaching a massive network but penalizes complexity throughout teaching. Yet another includes teaching a massive network and then “prunes” absent unimportant connections. Nevertheless another finds as economical an architecture as attainable by optimizing throughout numerous models—something called neural-architecture search. While every single of these tactics can provide important positive aspects for implementation, the outcomes on teaching are muted—certainly not sufficient to tackle the problems we see in our details. And in numerous situations they make the teaching prices increased.
One particular up-and-coming strategy that could decrease teaching prices goes by the name meta-discovering. The strategy is that the procedure learns on a wide range of details and then can be used in numerous parts. For instance, instead than creating individual methods to figure out pet dogs in pictures, cats in pictures, and cars and trucks in pictures, a solitary procedure could be skilled on all of them and utilised multiple moments.
However, modern do the job by
Andrei Barbu of MIT has unveiled how difficult meta-discovering can be. He and his coauthors showed that even compact discrepancies among the primary details and where you want to use it can seriously degrade general performance. They demonstrated that existing graphic-recognition methods count intensely on factors like irrespective of whether the item is photographed at a distinct angle or in a distinct pose. So even the simple task of recognizing the very same objects in distinctive poses results in the precision of the procedure to be nearly halved.
Benjamin Recht of the College of California, Berkeley, and other folks produced this issue even extra starkly, displaying that even with novel details sets purposely produced to mimic the primary teaching details, general performance drops by extra than 10 per cent. If even compact alterations in details bring about massive general performance drops, the details required for a complete meta-discovering procedure could possibly be great. So the wonderful guarantee of meta-discovering remains significantly from getting realized.
Yet another attainable method to evade the computational boundaries of deep discovering would be to shift to other, maybe as-nevertheless-undiscovered or underappreciated varieties of equipment discovering. As we explained, equipment-discovering methods produced all-around the perception of professionals can be significantly extra computationally economical, but their general performance cannot get to the very same heights as deep-discovering methods if individuals professionals simply cannot distinguish all the contributing aspects.
Neuro-symbolic solutions and other tactics are getting produced to blend the electricity of professional knowledge and reasoning with the flexibility frequently located in neural networks.
Like the circumstance that Rosenblatt faced at the dawn of neural networks, deep discovering is today turning out to be constrained by the accessible computational tools. Confronted with computational scaling that would be economically and environmentally ruinous, we need to possibly adapt how we do deep discovering or facial area a upcoming of significantly slower progress. Clearly, adaptation is preferable. A intelligent breakthrough could possibly discover a way to make deep discovering extra economical or laptop components extra effective, which would allow us to go on to use these terribly flexible designs. If not, the pendulum will likely swing back towards relying extra on professionals to detect what desires to be discovered.
From Your Site Posts
Associated Posts All over the Website







