
Ahana Cloud for Presto review: Fast SQL queries against data lakes
Hope springs eternal in the database enterprise. Even though we’re however listening to about info warehouses (quickly examination databases, typically showcasing in-memory columnar storage) and applications that boost the ETL action (extract, remodel, and load), we’re also listening to about advancements in info lakes (which retail store info in its indigenous format) and info federation (on-demand from customers info integration of heterogeneous info merchants).
Presto keeps coming up as a quickly way to perform SQL queries on big info that resides in info lake documents. Presto is an open up source distributed SQL question motor for running interactive analytic queries versus info sources of all measurements. Presto will allow querying info where it lives, like Hive, Cassandra, relational databases, and proprietary info merchants. A one Presto question can mix info from many sources. Fb works by using Presto for interactive queries versus quite a few internal info merchants, like their 300PB info warehouse.
The Presto Foundation is the corporation that oversees the advancement of the Presto open up source job. Fb, Uber, Twitter, and Alibaba founded the Presto Foundation. Added users now include things like Alluxio, Ahana, Upsolver, and Intel.
Ahana Cloud for Presto, the subject of this evaluate, is a managed support that simplifies Presto for the cloud. As we’ll see, Ahana Cloud for Presto operates on Amazon, has a fairly uncomplicated consumer interface, and has end-to-end cluster lifecycle management. It operates in Kubernetes and is highly scalable. It has a developed-in catalog and easy integration with info sources, catalogs, and dashboarding applications.
Opponents to Ahana Cloud for Presto include things like Databricks Delta Lake, Qubole, and BlazingSQL. I will attract comparisons at the end of the short article.
Presto and Ahana architecture
Presto is not a normal-intent relational database. Relatively, it is a device developed to effectively question broad quantities of info using distributed SQL queries. Even though it can exchange applications that question HDFS using pipelines of MapReduce positions such as Hive or Pig, Presto has been extended to function about various kinds of info sources like standard relational databases and other info sources such as Cassandra.
In quick, Presto is not developed for on line transaction processing (OLTP), but for on line analytical processing (OLAP) like info examination, aggregating huge quantities of info, and manufacturing reviews. It can question a large variety of info sources, from documents to databases, and return results to a selection of BI and examination environments.
Presto’s scalable, clustered architecture works by using a coordinator for SQL parsing, setting up, and scheduling, and a selection of employee nodes for question execution. Outcome sets from the personnel flow back to the customer by means of the coordinator.
Ahana Cloud deals managed Presto, a Hive metadata catalog, a info lake hosted on Amazon S3, cluster management, and entry to Amazon databases into what is proficiently a cloud info warehouse in an open up, disaggregated stack, as shown in the architecture diagram beneath. The Presto Hive connector manages entry to ORC, Parquet, CSV, and other info documents.
 Ahana
Ahana
As applied on AWS, Ahana Cloud for Presto areas the SaaS console outdoors of the customer’s VPC and the Presto clusters and Hive metastore within the customer’s VPC. Amazon S3 buckets serve as storage for info documents.
The Ahana handle plane will take treatment of cluster orchestration, logging, stability and entry handle, billing, and aid. The Presto clusters and the storage are living within the customer’s VPC.
Using Ahana Cloud for Presto
Ahana furnished me with a palms-on lab that authorized me to develop a cluster, hook up it to sources in Amazon S3 and Amazon RDS MySQL, and work out Presto using SQL from Apache Superset. Superset is a fashionable info exploration and visualization system. I didn’t definitely work out the visualization portion of Superset, as the stage of the work out was to glance at SQL overall performance using Presto.
 IDG
IDGWhen you develop a Presto cluster in Ahana, you opt for your instance styles for the coordinator, metastore, and personnel, and the initial selection of personnel. You can scale the selection of personnel up or down later on. For the reason that the datasets I was using ended up rather tiny (only millions of rows), I didn’t bother enabling I/O caching, which is a new feature of Ahana Cloud.
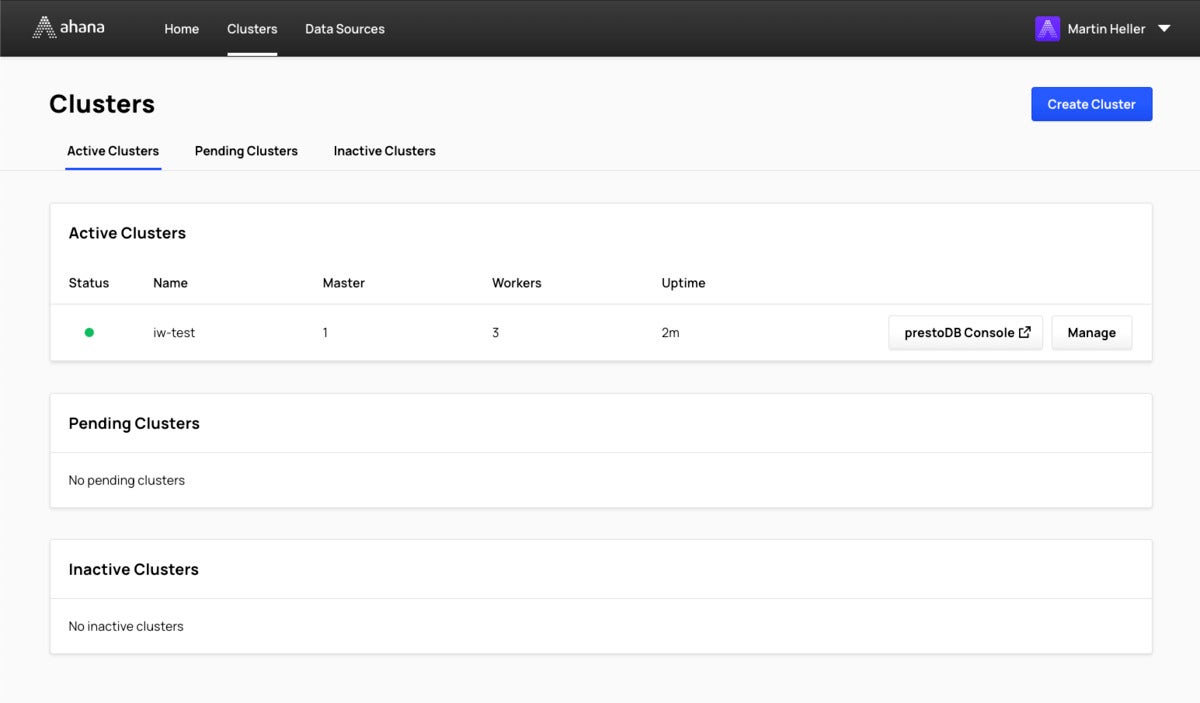 IDG
IDGThe Clusters pane of the Ahana interface displays your energetic, pending, and inactive clusters. The PrestoDB Console displays the standing of the running cluster.
I discovered the procedure of introducing info sources a bit aggravating because it required me to edit URI strings and JSON configuration strings. It would have been less difficult if the strings experienced been assembled from pieces in different text boxes, primarily if the text boxes ended up populated mechanically.
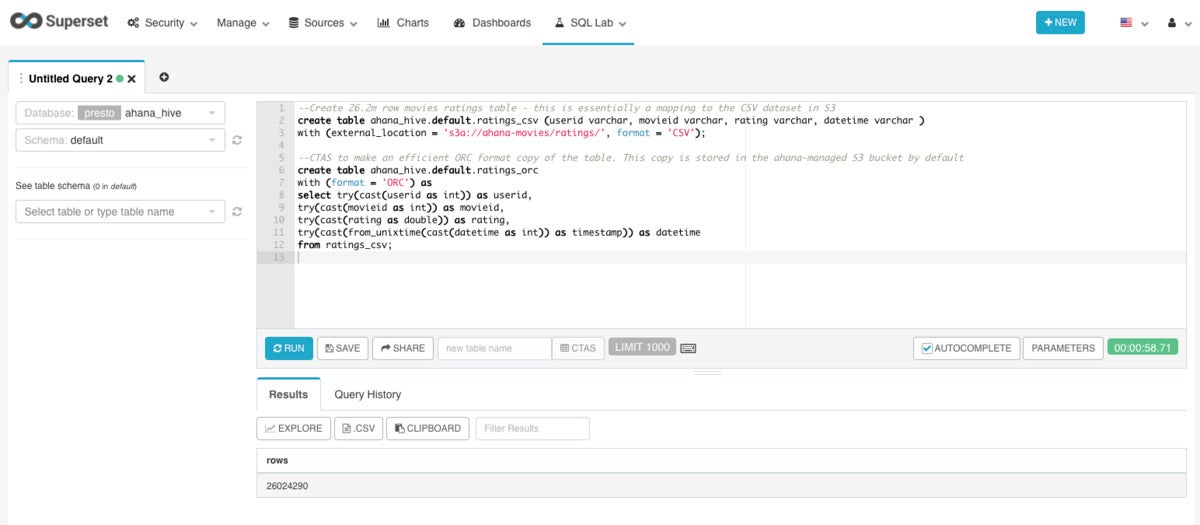 IDG
IDGMaking catalogs and converting from CSV to ORC format took just below a minute, for 26.2 million rows of film ratings. Querying an ORC file is much more quickly than querying a CSV file. For case in point, counting the ORC file will take 2.5 seconds, while counting the CSV file will take forty eight.6 seconds.
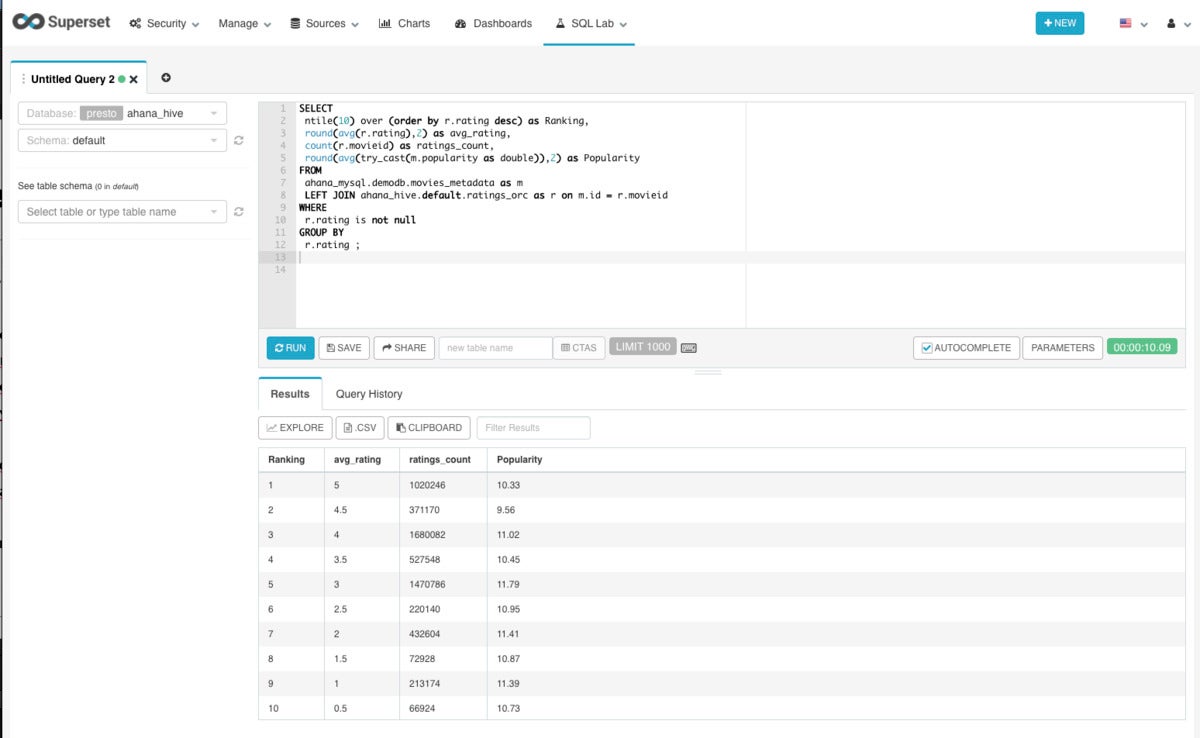 IDG
IDGThis federated question joins film ratings in ORC format with film info in a MySQL database table to develop a checklist of ratings, counts, and attractiveness damaged down into deciles. It took ten seconds.
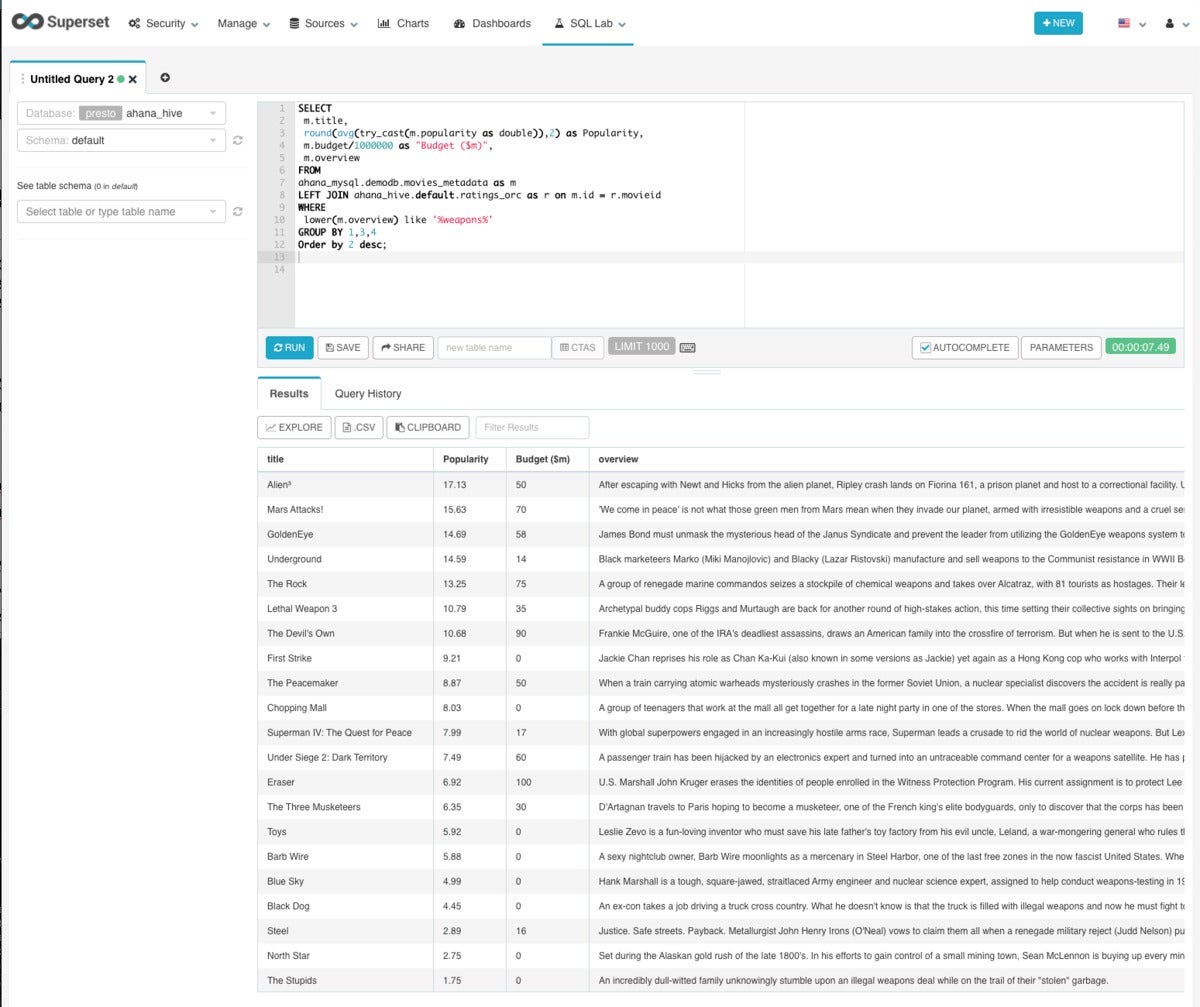 IDG
IDGThis question computes the most popular films in the federated database with a description that mentions weapons, and also reviews the movies’ budgets. The question took seven.5 seconds.
How to combine Ahana Presto with equipment understanding and deep understanding
How do people combine Ahana Presto with equipment understanding and deep understanding? Generally, instead than using Superset as a customer, they use a notebook, either Jupyter or Zeppelin. To perform the SQL question, they use a JDBC hyperlink to the Ahana Presto question motor. Then the output from the SQL question populates the appropriate structure or info body for use in equipment understanding, relying on the framework used.
New characteristics of Ahana Cloud for Presto
The version of Ahana Cloud I examined included the advancements introduced on March 24, 2021. These incorporated overall performance advancements such as info lake I/O caching and tuned question optimization, and ease of use advancements such as automatic and versioned upgrades of Ahana Compute Airplane.
I didn’t use all of them myself. For case in point, I didn’t permit info lake I/O caching because the info lake table I was using was too tiny, and I didn’t devote lengthy more than enough with Ahana to see a version improve.
Ahana Cloud for Presto vs. rivals
Overall, Ahana Cloud for Presto is a great way to convert a info lake on Amazon S3 into what is proficiently a info warehouse, without transferring any info. Using Ahana Cloud avoids most of the work required to set up and tune Presto and Apache Superset. SQL queries run speedily on Ahana Cloud for Presto, even when they are becoming a member of many heterogeneous info sources.
Qubole, a cloud-indigenous info system for analytics and equipment understanding, will help you to ingest datasets from a info lake, construct schemas with Hive, question the info with Hive, Presto, Quantum, and/or Spark, and keep on to your info engineering and info science. You can use Zeppelin or Jupyter notebooks, and Airflow workflows. In addition, Qubole will help you deal with your cloud expending in a system-impartial way. Not like Ahana, Qubole can run on AWS, Microsoft Azure, Google Cloud Platform, and Oracle Cloud.
BlazingSQL is an even more quickly way of running SQL queries, using Nvidia GPUs and running SQL on info loaded into GPU memory. BlazingSQL allows you ETL raw info right into GPU memory as GPU DataFrames. When you have GPU DataFrames in GPU memory, you can use RAPIDS cuML for equipment understanding, or change the DataFrames to DLPack or NVTabular for in-GPU deep understanding with PyTorch or TensorFlow.
Ahana Cloud for Presto is a worthwhile substitute to its rivals, and is less difficult to set up and retain than an open up source Presto deployment. It is definitely well worth the effort of a totally free trial.
—
Price: $.twenty five/Ahana Cloud Credit history (ACC) hour. See pricing calculator and table of instance fees. Example: Presto Cluster of ten x r5.xlarge running each and every workday fees $256/thirty day period.
Platform: Operates on Amazon Elastic Kubernetes Support.
Copyright © 2021 IDG Communications, Inc.





